Migrar AntD 4 a 5 con estilos less y adaptaciones de tema
Recientemente he estado trabajando junto con mi equipo en unos proyectos en react que utilizan la librería de AntD. El proyecto originalmente hace 5 años a la fecha de escribir este artículo. Durante estos años he ido migrando versiones de React y AntD hasta la 4.
Cuando los chicos de AntD publicaron la versión 5 le eché un vistazo y decidí esperar un poco a que estuviera algo más madura y cuando llegó el momento de migrar, llegaron los problemas, pues AntD elimina los estilos less.
Nosotros nos apoyamos en craco para hacer una adaptación de loaders de less en el proyecto de React, pero claro, esto ya no era posible en la versión AntD5. A continuación quiero detallar el proceso que seguimos en su momento para migrar la versión de AntD4 a AntD5 y no perder los estilos customizados por el camino.
Existe una guía de migración de AntD 4 a AntD 5, donde detallan los cambios entre la versión 4 y 5 de la librería y los pasos a seguir.
Lo primero, bastante obvio, es actualizar el paquete de AntD a su versión 5.
Una vez migrado, vamos a ver que hacemos con less. En nuestro caso, como ya utilizamos un loader de craco de less para babel, no tenemos que hacer nada especial que no aparezca en la guía. Tenemos que añadir el paquete @ant-design/compatible que lo haremos con el comando
yarn add @ant-design/compatible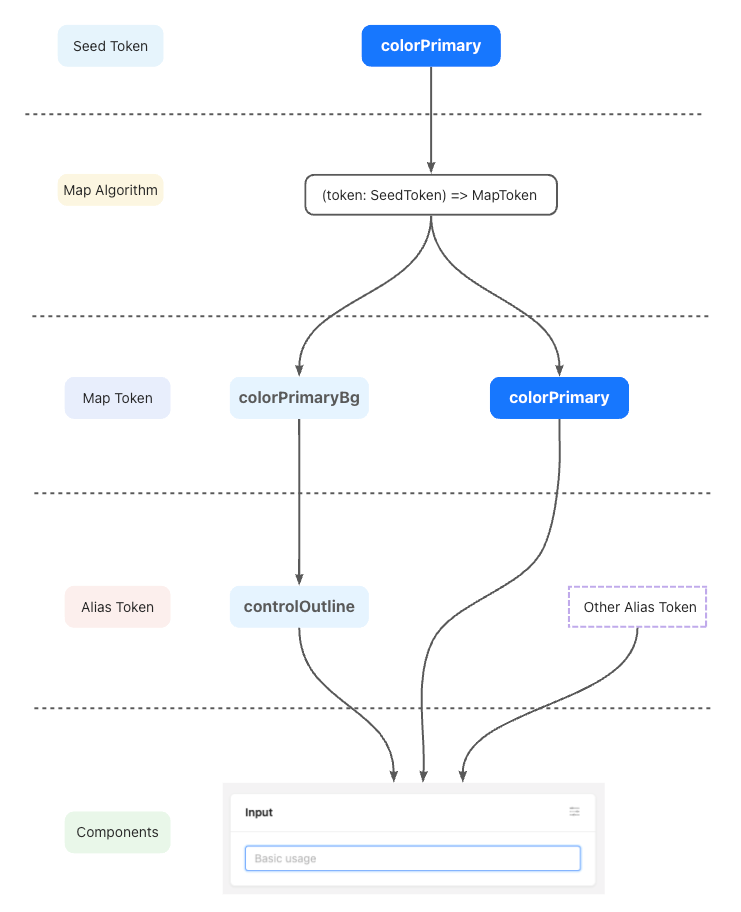
Desde la versión 5 de AntD, ya no se utiliza less sino unos estilos que se denominan css-in-js, por lo a través de una paquete de compatibilidad tenemos que habilitar los estilos de less. Esto no es 100% necesario, depende de cada proyecto. En nuestro archivo de configuración de craco tenemos que crear lo que han llamado theme y tokens. Viene muy bien explicado en la documentación de forma gráfica donde tenemos los seed que son las semillas del template (si queremos temas claros, oscuros, etc) y de ahí descienden los mapas y tokens que generarán el estilo visual final. Para que todo funcione incluiremos el siguiente código en nuestro inicio, da igual si es craco o cualquier otro sistema de adaptación.
const { convertLegacyToken } = require('@ant-design/compatible/lib');
const { theme } = require('antd/lib');
const { defaultAlgorithm, defaultSeed } = theme;
const seed = {
...defaultSeed,
colorPrimary: '#EB4034', //Adaptación de less del color primario
colorBgContainer: '#FAFEFE' //Adaptación de less del fondo del contenedor
};
const mapToken = defaultAlgorithm(seed);
const v4Token = convertLegacyToken(mapToken);
...
loader: 'less-loader',
options: {
lessLoaderOptions: {
lessOptions: {
modifyVars: v4Token /* {
'@primary-color': '#EB4034',
'@layout-body-background': '#FAFEFE',
'@select-item-selected': 'white'
} */,
javascriptEnabled: true
}
}
}En nuestro caso la adaptación era muy sencilla, en lugar de enviar a less las variables sobrescritas, hay que pasar el token generado con esas mismas variables sobrescritas.
El siguiente paso se trata de modificar los archivos less. En nuestro caso teníamos como primera linea del archivo App.less en el raíz de la carpeta src la siguiente línea que es necesaria comentar:
//@import '~antd/dist/antd.less';Si no quitamos esta linea estamos forzando a traer el less si está en el node_modules, pues en nuestro caso es un monorepo donde hemos empezado a migrar primero un proyecto pequeño y puede existir (en la versión 5 de AntD no debería existir y daría error).
Bien, ya lo tenemos listo pero el theme nos aparece en azul. Hasta aquí fue todo sencillo ya que el siguiente paso no es como tal de la migración sino de leer la nueva documentación de AntD5. La sobrescritura de variables en esta nueva versión se hace a través de un ConfigProvider. En nuestro proyecto ya utilizabamos dicho ConfigProvider para forzar el locale a español.
En nuestro proyecto, el ConfigProvider engloba al Router que es el React-Router de la aplicación de la siguiente manera:
<ConfigProvider
locale={es_ES}
theme={{
algorithm: theme.defaultAlgorithm,
token: { colorPrimary: '#EB4034', colorBgLayout: '#FAFEFE' }
}
}>
</Routes>
</ConfigProvider>Espero que os haya servido de ayuda.
Migrar AntD 4 a 5 con estilos less y adaptaciones de tema Leer más »











